
We use machine learning every day – often without even thinking about it. We’ve grown accustomed to Netflix or Amazon offering suggestions on what we want to buy or watch next and almost expect Google to be able to finish our thoughts as we type our search. Beyond shopping and internet browsing, Machine Learning and Deep Learning are breakthrough technologies enabling significant leaps forward in solving a wide variety of problems. At Flowstate, we are using them to deliver an innovative approach to pipeline leak detection. We have shown that it offers solutions to many of the issues that have made leak detection so challenging to implement.
As we’ve been talking to people about machine learning and its application in this area, we have found a couple common themes: There is still some curiosity over what Machine Learning is, and people are very interested to hear how it can aid in leak detection. This is a discussion we love to have, and so I’m going to spend some time here digging into both in a two-part series. First, I thought I’d address some of the curiosity around machine learning by answering some common questions. Then, in the second part, I will dig into how we are using the technology and the benefits it has produced.
QUICK NAVIGATION:
Question 1: What is the difference between Machine Learning and Deep Learning?
Question 2: Can machine learning be trusted?
Question 4: Is machine learning difficult or complicated to use?
Question 5: Is there a real benfit in machine learning over existing methods, or is it just a fad?
Question 1: What is the difference between Machine Learning and Deep Learning?
Although these technologies are growing more prevalent, it may still be helpful to get an orientation (or refresher) on what they are and what is the difference between them. There are, of course, entire articles just on that topic – and if you are interested in reading more, I encourage you to check out some of the links below. But here is a short synopsis for our purposes.
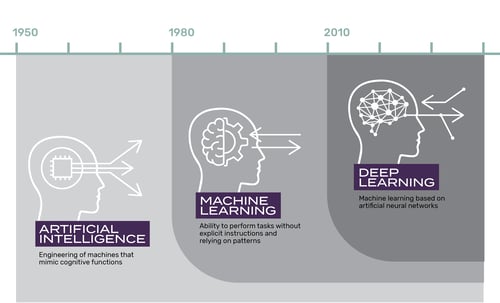
Image Source: Shutterstock
Artificial Intelligence (AI) is an umbrella term used to broadly describe the ability for a machine to mimic “cognitive” functions of a human. This can start as simple as programing a computer to execute specific tasks given a specific set of rules (think “if X, then Y, else Z”). But anyone who has tried to program a robot knows - even simple tasks can be quite complex for a computer. Defining explicit functions is no match for the power of the human brain to learn, analyze, and make decisions.
Machine Learning represents an evolution of artificial intelligence. It is a subset of AI that uses algorithms to train – with human some input, like labeling pictures of dogs and cats) - on a data set and learn to process and act on that data with little to no further human intervention.
Deep Learning takes this even further by mimicking human perception. A neural network algorithm - inspired by our brain and the connection between neurons - is able to learn the features required to solve the problem without requiring input from the human to define those them explicitly. This is key! Defining the rules, described as “feature extraction” in the image below, is typically a complicated process and involves a lot of knowledge and involvement from a human. With a large data set, deep learning’s neural networks are able to take on that role by recognizing the features and learning the rules on its own.
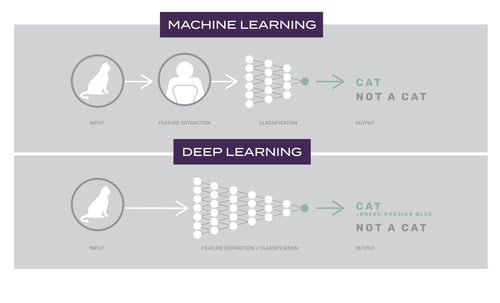
Image Source: Toward Data Science
This provides a good illustration of why we are using Deep Learning in our application. Machine learning alone would require much more human engineering in defining the physics of the pipeline. Instead, our deep learning neural networks are trained on large amounts of a pipeline’s operational data and are able to learn the complex interactions.
You can read more about how Flowstate is utilizing deep learning in part two of this series.
Here are a couple great articles that give a more in-depth description of machine learning and deep learning:
Deep Learning vs. Machine Learning — What’s the Difference? (Flatiron School – Feb 2021)
Artificial Intelligence vs. Machine Learning vs. Deep Learning (Toward Data Science – Oct 2019)
We are using deep learning at Flowstate. However, the remaining questions address both machine learning (ML) and deep learning (DL). As such, I will sometimes just use the term machine learning (ML) for simplicity.
Question 2: Can machine learning be trusted?
Anyone who’s been confused about a seemingly random movie or product suggestion may wonder: can we trust ML in an application like pipeline leak detection?
There are two things to note here. First, ML models can actually be more reliable than human calculations. Computers and explicitly defined algorithms can run continuously and with high levels of accuracy, avoiding issues with human limitations of attention, focus, and errors. In addition, they can learn very detailed aspects of a dataset, overcome human limitations of bias and achieve a better representation of the system than we might be able to otherwise.
Secondly, there's a lot that goes in to validating the data and ensuring that the results from the model are correct. The training process involved in building the DL models tests the predictions against actual data to confirm that it is computing reasonable answers. At Flowstate, when we are building a DL model to predict output flowrate, we are able to test the predicted flow rate against the actual measured output flow rate. (More on that in Part 2.) We measure that error in our predictions and aim to ensure that error is minimized. In addition, the Flowstate LDS implementation has been tested in over 150 leak simulations (commodity withdrawal tests) on a variety of segments and operational conditions. Results show that well trained machine learning models do an excellent job of learning normal operations and accurately identifying anomalies presented by leaks.
Question 3: Can you use machine learning to detect leaks if there isn’t enough leak data to learn from?
Some may wonder if we can use machine learning in pipeline leak detection if there are not enough examples of real leaks for the system to “learn” from. This view is perhaps caused by a limited understanding about the different kinds of ML and how they can be applied. We frequently hear of ML applied in classification problems, i.e., is this photo a dog or cat? In the context of leak detection, one might imagine the ML model observing data and determining “leak” or “not a leak”? This would be a valid implementation of ML, but not how we’re applying it at Flowstate - precisely because we don’t have enough examples of real leaks to build a generic and robust solution. Instead, we are treating this as a regression problem – essentially, we're training ML models to learn what normal operational behaviors look like so that it can accurately estimate what flow should be coming out of the pipeline (based on input flow rates, pressures, etc.). In this sense our ML models learn to approximate the physics of the system so that we can look for deviations from normal behavior that might be associated with a leak. We can apply logic, thresholds, etc. on top of those to help determine when the operator should be alarmed of these deviations or anomalies.
Question 4: Is machine learning difficult or complicated to use?
When considering ML, people often wonder if it is difficult to use. Does it require extensive hardware to implement? It is time intensive, and does it require a lot of user training?
From a user perspective, the ML employed by Flowstate is utilized completely behind the scenes. The operator only sees the results – and need not even know they are a result of machine learning!
The creation of the machine learning models is not difficult either. The ML models that power the Flowstate LDS require a little as three weeks of data to learn from and are designed to use data already collected on the pipeline. With modern computing resources, model development and acceptance testing can usually be completed in just a few weeks after that. The models are trained on machines owned by Flowstate, but once created, they can be utilized in the cloud or on relatively inexpensive and common computers onsite. The results are incorporated into an intuitive and easy to use interface.
The entire process of utilizing machine learning in the Flowstate LDS is not as difficult or cumbersome to use as one might think. In fact, when compared to other leak detection methods such as RTTM, it can seem quite simple. Training a ML model can be completed in days or even hours and requires almost no human intervention – compared to weeks or months needed to tune a complex hydraulic model with multiple inputs and parameters. What’s more, imagine you have a change in your pipeline operations (new injection or change in flow profile) and have to start all over with either method! Having the ability to quickly retrain the ML model (vs. re-tuning a hydraulic model) minimizes the disruption caused by operational changes which frequently occur.
Question 5: Is there real benefit in machine learning over existing methods, or is it just a fad?
“Artificial Intelligence, deep learning, machine learning — whatever you’re doing if you don’t understand it — learn it. Because otherwise, you’re going to be a dinosaur within 3 years.” - Mark Cuban
Machine learning is becoming a bit of a buzz word. It has emerged as a topic at many conferences and trade shows. It can be tempting to think that ML is just a shiny object or a fad. However, machine learning offers a dramatic improvement over other methods of pipeline leak monitoring.
To date, one of the more sophisticated methods for leak detection is utilizing a Real Time Transient Model (RTTM) to estimate expected flow rate. The RTTM method requires significant resources in instrumentation and engineering and is still shown to be prone to error when conditions change or if parameters were not set accurately. Deep Learning has been shown to perform very well at learning a pipeline’s hydraulics and since it can be used with less instrumentation and less complicated engineering cycle, it can be an effective substitute in approximating the physics. In the Flowstate LDS, DL has been shown to rival the performance of a sophisticated model, detecting leaks as small as 1% of flowrate. For these reasons, we believe ML does indeed offer real benefit and is not just a fad, but rather a transformative technology that will have a meaningful impact in the industry.

Comments
Add Comment